第一步:手写数字识别是什么任务?
MNIST 是机器学习中最经典的入门数据集之一。每张图片都是一个 28×28 的灰度手写数字,
模型要根据这些像素判断它属于 0 到 9 中的哪一类。
数据已随页面部署,加载速度取决于网速,通常数秒即可完成。所有训练和推理均在本地浏览器完成,无需持续联网。
○图片精灵图(10 MB)
○标签文件(635 KB)
正在连接,请稍候……
输入与输出
$$x = [x_1, x_2, \ldots, x_{784}]$$
$$\hat{y} = [p_0, p_1, \ldots, p_9]$$
从图片到分类
一张 28×28 图片会被看作 784 个数字。模型输出 10 个概率,分别表示它认为这张图是 0、1、2……9 的可能性。
一张 28×28 图片会被看作 784 个数字。模型输出 10 个概率,分别表示它认为这张图是 0、1、2……9 的可能性。
MNIST 数据集简介
MNIST 是一个由手写数字图片组成的经典数据集,常用于机器学习入门教学。完整训练集约有 60,000 张图片,测试集约有 10,000 张图片。
本页面为了课堂演示和浏览器性能,只加载其中一部分样本:训练时可选择 1,000 到 5,000 张,评估时最多抽取 1,000 张测试样本。
MNIST 是一个由手写数字图片组成的经典数据集,常用于机器学习入门教学。完整训练集约有 60,000 张图片,测试集约有 10,000 张图片。
本页面为了课堂演示和浏览器性能,只加载其中一部分样本:训练时可选择 1,000 到 5,000 张,评估时最多抽取 1,000 张测试样本。
第二步:把 28×28 图片展开成 784 个输入
MLP 不直接“看见”二维图片结构。它接收的是一串数字:每个像素的灰度值都会变成一个输入特征。
移动鼠标到像素上,观察灰度值。
归一化后的输入向量 x(片段)
$x = [\text{请先加载一个数字样本}]$
这里只展示部分像素值;完整输入向量共有 784 个数字。
像素灰度
$$0 \leq x_i \leq 1$$
$$28 \times 28 = 784$$
输入向量从哪里来?
一张 28×28 的黑白数字图片,会被转换成一个 784 维输入向量。向量中的每一维,对应图片里的一个像素灰度值。
原始灰度值通常在 0 到 255 之间:0 表示黑色,255 表示白色。训练前,我们把它缩放到 0 到 1 之间,这一步叫做归一化,可以让模型计算更稳定。
一张 28×28 的黑白数字图片,会被转换成一个 784 维输入向量。向量中的每一维,对应图片里的一个像素灰度值。
原始灰度值通常在 0 到 255 之间:0 表示黑色,255 表示白色。训练前,我们把它缩放到 0 到 1 之间,这一步叫做归一化,可以让模型计算更稳定。
这样输入丢失了什么信息?
展开成向量后,模型看到的是一串数字,而不是一张二维图片。虽然每个像素值都保留了,但像素之间的空间关系被弱化了:哪些像素彼此相邻、哪些笔画连在一起,模型不能直接知道。
后续可以用其他策略来保留或利用这种空间关系,让图像识别做得更好。
展开成向量后,模型看到的是一串数字,而不是一张二维图片。虽然每个像素值都保留了,但像素之间的空间关系被弱化了:哪些像素彼此相邻、哪些笔画连在一起,模型不能直接知道。
后续可以用其他策略来保留或利用这种空间关系,让图像识别做得更好。
第三步:搭建一个简单的 MLP(Multilayer Perceptron,多层感知机)
这个网络只有输入层、一个隐藏层和输出层。隐藏层会把 784 个像素重新组合成一些中间特征,输出层再给出 10 个数字类别的概率。
为什么这里的网络这么简单?
为了让它能在大家的电脑上直接训练和运行,我们这里故意把网络做得很简单;实际应用中的神经网络通常会有更多隐藏层,也就是更“深”。
为了让它能在大家的电脑上直接训练和运行,我们这里故意把网络做得很简单;实际应用中的神经网络通常会有更多隐藏层,也就是更“深”。
ReLU 函数图像
| 层 | 规模 | 作用 |
|---|---|---|
| 输入层 | 784 | 接收像素灰度 |
| 隐藏层 | 学习中间特征 | |
| 输出层 | 10 | 输出类别概率 |
MLP 计算
$$h = ReLU(\textcolor{orange}{W_1}x + \textcolor{orange}{b_1})$$
$$\hat{y} = Softmax(\textcolor{orange}{W_2}h + \textcolor{orange}{b_2})$$
什么是多层感知机?
MLP 是 Multilayer Perceptron 的缩写,中文常译为多层感知机。可以把它理解为由多层神经元连接起来的普通前馈神经网络:信息从输入层流向隐藏层,再流向输出层。
MLP 是 Multilayer Perceptron 的缩写,中文常译为多层感知机。可以把它理解为由多层神经元连接起来的普通前馈神经网络:信息从输入层流向隐藏层,再流向输出层。
ReLU:修正线性单元
ReLU 是 Rectified Linear Unit 的缩写,中文常译为修正线性单元。之前我们认识过 Sigmoid,这里使用的是另一种更常见的激活函数:
$$ReLU(z)=\max(0,z)$$ 它的作用是引入非线性:如果输入小于 0,就输出 0;如果输入大于 0,就保留原值。这样网络就不只是做简单的线性计算。
ReLU 是 Rectified Linear Unit 的缩写,中文常译为修正线性单元。之前我们认识过 Sigmoid,这里使用的是另一种更常见的激活函数:
$$ReLU(z)=\max(0,z)$$ 它的作用是引入非线性:如果输入小于 0,就输出 0;如果输入大于 0,就保留原值。这样网络就不只是做简单的线性计算。
Softmax:把分数变成概率
输出层会先得到 10 个分数,分别对应数字 0 到 9。Softmax 会把这些分数转换成概率:
$$p_i=\frac{e^{z_i}}{\sum_j e^{z_j}}$$ 转换后,每个 $p_i$ 都在 0 到 1 之间,并且 10 个概率之和等于 1。概率最大的那个数字,就是模型当前最相信的预测结果。
输出层会先得到 10 个分数,分别对应数字 0 到 9。Softmax 会把这些分数转换成概率:
$$p_i=\frac{e^{z_i}}{\sum_j e^{z_j}}$$ 转换后,每个 $p_i$ 都在 0 到 1 之间,并且 10 个概率之和等于 1。概率最大的那个数字,就是模型当前最相信的预测结果。
学习的对象
模型不会记住“判断 7 的规则”,而是在训练中不断调整权重和偏置,让正确类别的概率越来越高。
模型不会记住“判断 7 的规则”,而是在训练中不断调整权重和偏置,让正确类别的概率越来越高。
第四步:在浏览器中训练模型
选择一个小规模训练设置,然后观察损失值和准确率如何变化。为了照顾普通电脑,默认只抽取部分 MNIST 样本。
等待开始训练。
训练参数小词典
• 样本数:本次从 MNIST 中取多少张图片来训练。样本越多,信息越充分,但浏览器计算时间也越长。
• Epoch:模型把这些训练样本完整看一遍,叫做 1 个 epoch。多个 epoch 表示反复看同一批样本,并多次通过反向传播调整参数。
• 学习率:每次根据梯度更新权重时,迈出的步子有多大。太小会学得慢,太大可能越过比较好的参数位置。
• 样本数:本次从 MNIST 中取多少张图片来训练。样本越多,信息越充分,但浏览器计算时间也越长。
• Epoch:模型把这些训练样本完整看一遍,叫做 1 个 epoch。多个 epoch 表示反复看同一批样本,并多次通过反向传播调整参数。
• 学习率:每次根据梯度更新权重时,迈出的步子有多大。太小会学得慢,太大可能越过比较好的参数位置。
Epoch
0
Loss
--
Accuracy
--
| 轮次 | Loss | Accuracy |
|---|---|---|
| 训练后将在这里记录每一轮的结果 | ||
怎么看曲线?
Loss 越低,表示模型整体错误越小;Accuracy 越高,表示预测正确的比例越高。小样本和 MLP 的准确率不必追求满分,重点是看见“学习”的过程。
Loss 越低,表示模型整体错误越小;Accuracy 越高,表示预测正确的比例越高。小样本和 MLP 的准确率不必追求满分,重点是看见“学习”的过程。
性能提示
训练完全在本机浏览器中进行。样本越多、轮数越多,耗时越长;低配电脑可以选择 1000 张样本和 1 轮训练。
训练完全在本机浏览器中进行。样本越多、轮数越多,耗时越长;低配电脑可以选择 1000 张样本和 1 轮训练。
第五步:写一个数字,让模型试着识别
在黑色画布上写一个白色数字。页面会把你的笔迹缩放成 28×28 像素,再交给模型输出 10 个类别概率。
当前模型状态
来源
空白 MLP 模型
结构
784 → 64 → 10
Accuracy
尚未训练
Loss
尚未训练
预测数字
?
模型看到的 28×28 输入
概率不是绝对答案
如果模型还没训练,或者手写风格与 MNIST 差异较大,预测会不稳定。观察概率分布,比只看最终数字更重要。
如果模型还没训练,或者手写风格与 MNIST 差异较大,预测会不稳定。观察概率分布,比只看最终数字更重要。
第六步:导出、导入和本地保存模型
训练完成后,模型的结构和参数可以保存下来。下次导入后,不需要重新训练就能继续推理。
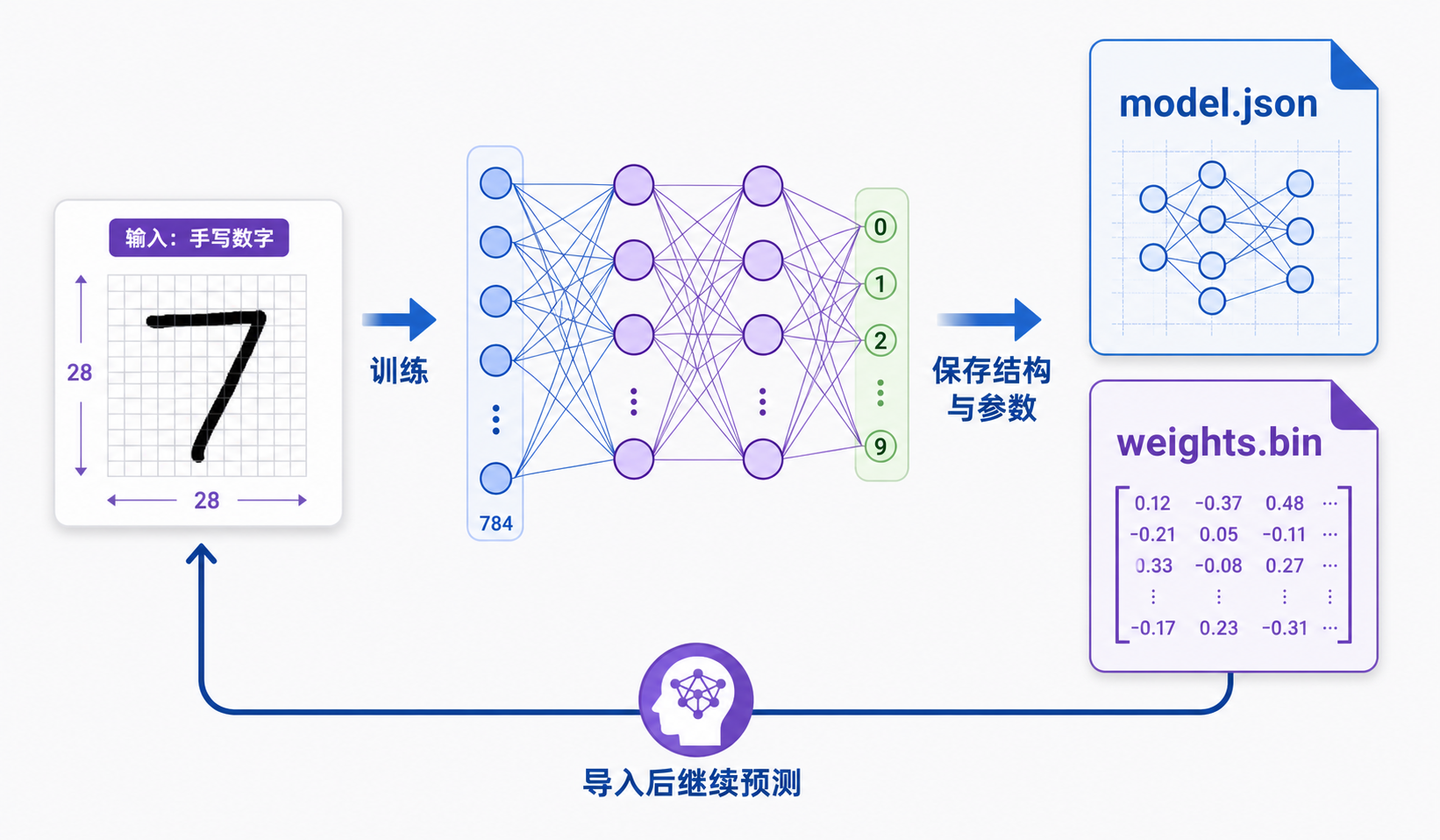
保存下来的是什么?
model.json:记录网络结构,例如输入维度、隐藏层大小、输出层以及每一层的连接方式。
weights.bin:记录训练后得到的权重和偏置,也就是模型真正“学会”的参数。
模型会保存在你的设备上,不会上传到服务器。
下载教师预置模型
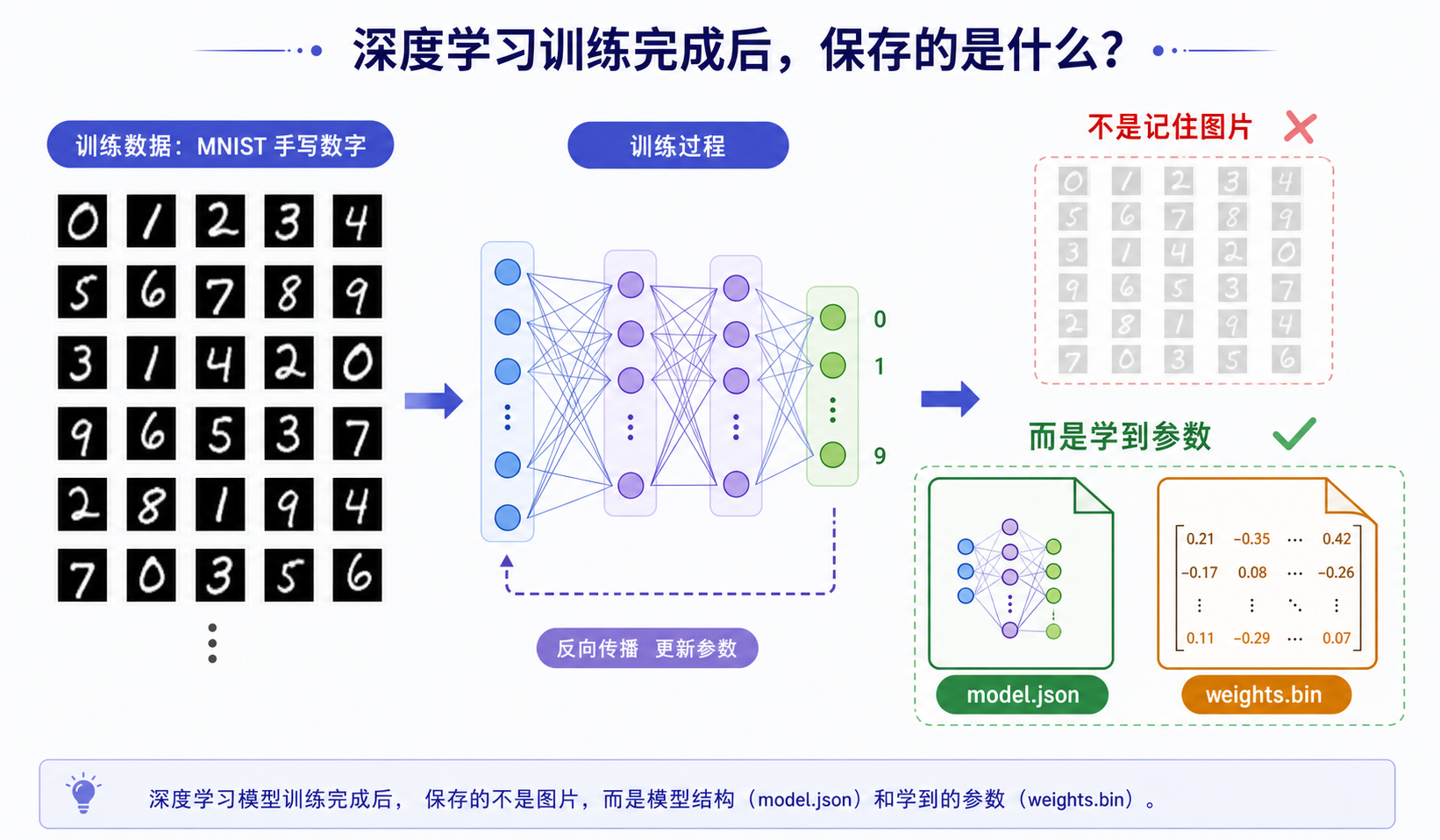 深度学习到底在“学习”什么?
深度学习到底在“学习”什么?
训练并不是把所有手写图片背下来,而是通过反向传播不断调整权重和偏置。保存模型时,最重要的就是保存这些被调整过的参数。
导入模型,就是把之前学到的参数重新装回网络中,因此不重新训练也能继续进行手写数字识别。
深度学习到底在“学习”什么?训练并不是把所有手写图片背下来,而是通过反向传播不断调整权重和偏置。保存模型时,最重要的就是保存这些被调整过的参数。
导入模型,就是把之前学到的参数重新装回网络中,因此不重新训练也能继续进行手写数字识别。
第七步:从贝尔实验室到你的浏览器——MNIST 与 LeNet 的故事
你刚刚训练的这个网络,并不是凭空出现的。它背后有四十年的研究积累、一段关于"数据该怎么收集"的历史教训,以及一句让整个学科记住的比喻。
MNIST 与 LeNet:一条时间线
人物
Yann LeCun(1960–)
法国计算机科学家,1980 年代在贝尔实验室(Bell Labs)研究卷积神经网络与反向传播算法。2018 年与 Hinton、Bengio 共同获得图灵奖,被称为"深度学习三巨头"之一。
法国计算机科学家,1980 年代在贝尔实验室(Bell Labs)研究卷积神经网络与反向传播算法。2018 年与 Hinton、Bengio 共同获得图灵奖,被称为"深度学习三巨头"之一。
1989
LeNet 初代:读取邮政编码
LeCun 设计卷积神经网络,用于自动识别美国邮件上的手写邮政编码。美国邮政系统(USPS)开始小规模试用,这是深度学习最早的真实部署场景之一。
LeCun 设计卷积神经网络,用于自动识别美国邮件上的手写邮政编码。美国邮政系统(USPS)开始小规模试用,这是深度学习最早的真实部署场景之一。
1998
LeNet-5:读取银行支票
LeNet-5 发布,被 NCR(原美国国家收银机公司)和 AT&T 部署用于自动识别银行支票上的手写金额。鼎盛时期,每天处理数以百万计的支票——这是深度学习在商业上最早的大规模落地案例之一。
LeNet-5 发布,被 NCR(原美国国家收银机公司)和 AT&T 部署用于自动识别银行支票上的手写金额。鼎盛时期,每天处理数以百万计的支票——这是深度学习在商业上最早的大规模落地案例之一。
1994–1998
MNIST 数据集的由来
原始数据来自 NIST(美国国家标准与技术研究院):训练集由人口普查局雇员手写,测试集由高中生手写。两组人群书写习惯不同,分布不一致,导致测试指标失真。
LeCun、Cortes、Burges 将两组数据混合重新划分,制作出 60,000/10,000 的新训练/测试集。"M"就是 Modified 的缩写——这就是 MNIST 名字的由来。
原始数据来自 NIST(美国国家标准与技术研究院):训练集由人口普查局雇员手写,测试集由高中生手写。两组人群书写习惯不同,分布不一致,导致测试指标失真。
LeCun、Cortes、Burges 将两组数据混合重新划分,制作出 60,000/10,000 的新训练/测试集。"M"就是 Modified 的缩写——这就是 MNIST 名字的由来。
一个数据集诞生背后的教训
MNIST 的诞生本身就是一堂关于"训练集与测试集必须同分布"的课。用一群人的字迹训练、拿另一群人的字迹测试,指标会失真——这个问题今天依然是机器学习实践中最常见的陷阱之一。
MNIST 的诞生本身就是一堂关于"训练集与测试集必须同分布"的课。用一群人的字迹训练、拿另一群人的字迹测试,指标会失真——这个问题今天依然是机器学习实践中最常见的陷阱之一。
2006
Hinton 的比喻
Geoffrey Hinton 将 MNIST 称为"机器学习界的果蝇"(the drosophila of machine learning)。就像生物学家用果蝇研究遗传,机器学习研究者用 MNIST 验证新算法。一个简单标准的数据集,塑造了整个学科二十年的研究范式。
Geoffrey Hinton 将 MNIST 称为"机器学习界的果蝇"(the drosophila of machine learning)。就像生物学家用果蝇研究遗传,机器学习研究者用 MNIST 验证新算法。一个简单标准的数据集,塑造了整个学科二十年的研究范式。
2012+
ImageNet 复兴与 MNIST 的"退休"
AlexNet 在 ImageNet 大赛上引爆深度学习复兴。与此同时,MNIST 因为"太容易"而被批评——现代网络轻松达到 99.7% 以上的准确率,无法再区分算法优劣。
这催生了 Fashion-MNIST(2017)、EMNIST、QMNIST 等更有挑战性的替代数据集。
AlexNet 在 ImageNet 大赛上引爆深度学习复兴。与此同时,MNIST 因为"太容易"而被批评——现代网络轻松达到 99.7% 以上的准确率,无法再区分算法优劣。
这催生了 Fashion-MNIST(2017)、EMNIST、QMNIST 等更有挑战性的替代数据集。

从贝尔实验室到你的浏览器
1989 年
一台工作站、一小批邮政编码图片、几周训练
1998 年
每天数百万张银行支票自动识别
今天
浏览器中,60,000 张图片,几十秒训练完毕
同样的核心思想(卷积 + 加权求和 + 反向传播),跨越四十年,
运行在从巨型服务器到手机浏览器的各种硬件上。
MNIST 的两个身份
作为工具:一个标准测试场景,帮助研究者快速验证新算法,三十年来从未被取代的基准。
作为镜子:它折射出机器学习最基本的问题——数据从哪里来、谁收集的、为谁服务。一个"干净"的数据集背后,往往藏着被简化掉的现实复杂性。
作为镜子:它折射出机器学习最基本的问题——数据从哪里来、谁收集的、为谁服务。一个"干净"的数据集背后,往往藏着被简化掉的现实复杂性。
核心方法几十年没变,变的是规模与算力
从 LeNet-1 到今天的大语言模型,核心计算单元始终是:局部感受野 / 加权求和 → 非线性激活 → 反向传播更新参数。你在第三步搭建的那个 MLP,和 LeCun 1989 年 的代码共享同一套数学骨架。差异在于:参数量从几千变成了数千亿,数据从几张图片 变成了整个互联网。
从 LeNet-1 到今天的大语言模型,核心计算单元始终是:局部感受野 / 加权求和 → 非线性激活 → 反向传播更新参数。你在第三步搭建的那个 MLP,和 LeCun 1989 年 的代码共享同一套数学骨架。差异在于:参数量从几千变成了数千亿,数据从几张图片 变成了整个互联网。
第八步:当模型走进教室——公平、指标与人的判断
LeNet 读邮编是效率的胜利。但当同样的技术被用于批改作业、识别学习困难、评估学生表现时,我们需要追问三个问题:数据从哪来?对谁不公平?指标之外丢了什么?
把模型带进教室之前,问三个问题
①
训练数据从哪里来?
MNIST 的训练集来自人口普查局雇员——成年人、有稳定书写习惯的群体。用它训练的模型,遇到儿童歪斜的笔迹、左利手的书写、或是从没见过的字体,识别率会显著下降。
教育场景中:数据来自哪个学校?哪一届学生?和你要预测的群体有多相似?
MNIST 的训练集来自人口普查局雇员——成年人、有稳定书写习惯的群体。用它训练的模型,遇到儿童歪斜的笔迹、左利手的书写、或是从没见过的字体,识别率会显著下降。
教育场景中:数据来自哪个学校?哪一届学生?和你要预测的群体有多相似?
②
指标衡量的是什么?
99% 的准确率意味着每 100 张图里大约有 1 张识别错误。但这 1 张"错误"——是把"1"认成"7",还是始终无法识别某种书写风格?指标把它们一视同仁,但影响并不相同。
教育场景中:考试分数高不等于真正理解;一个平均指标背后,往往隐藏着个体差异。
99% 的准确率意味着每 100 张图里大约有 1 张识别错误。但这 1 张"错误"——是把"1"认成"7",还是始终无法识别某种书写风格?指标把它们一视同仁,但影响并不相同。
教育场景中:考试分数高不等于真正理解;一个平均指标背后,往往隐藏着个体差异。
③
自动化决策中,人在哪里?
OCR 阅卷系统把识别结果直接计入成绩,没有人工复核——效率极高,但当系统对某类学生系统性地误判时,后果由谁承担?
技术工具放大效率,也放大错误。教师的判断力不是可以被替代的"慢",而是系统需要的"校验"。
OCR 阅卷系统把识别结果直接计入成绩,没有人工复核——效率极高,但当系统对某类学生系统性地误判时,后果由谁承担?
技术工具放大效率,也放大错误。教师的判断力不是可以被替代的"慢",而是系统需要的"校验"。
⚠️
数据偏见与公平
干净数据集背后的隐形边界
MNIST 里的数字:居中、大小适中、黑白分明,标准得像教科书印刷体。
真实的手写字迹是:歪斜、压线、笔画断开——尤其是低年级学生、特殊需要学生、 初学中文数字的非母语学生。
当 AI 阅卷系统遇到这些字迹,识别率会下降;而系统的错判, 会不成比例地落在最需要帮助的那部分学生身上。
真实的手写字迹是:歪斜、压线、笔画断开——尤其是低年级学生、特殊需要学生、 初学中文数字的非母语学生。
当 AI 阅卷系统遇到这些字迹,识别率会下降;而系统的错判, 会不成比例地落在最需要帮助的那部分学生身上。
📊
唯指标崇拜
一个数字统治不了全部真相
MNIST 上的 99% 准确率,让整个学科围绕它比拼了二十年——直到大家意识到,
这个数字已经无法区分好算法和坏算法,它反映的是"在这个特定数据集上的得分",
而非"理解数字的能力"。
高分不等于真正理解,低分不等于一无所知。 用单一指标评价学习,和用 MNIST 准确率评价智能,面对的是同一个问题。
高分不等于真正理解,低分不等于一无所知。 用单一指标评价学习,和用 MNIST 准确率评价智能,面对的是同一个问题。
🤝
自动化与人的判断
效率是起点,不是终点
LeNet 读邮编,把邮政工人从机械重复的工作中解放出来——这是自动化最好的一面。
但判断"这个孩子是在偷懒还是遇到了理解障碍"、"这道题的解法虽然格式不标准但思路正确", 需要的不是准确率,而是情境理解与职业判断——这正是教师区别于模型的地方。
AI 工具可以帮你做更多,但不能替你承担判断的责任。
但判断"这个孩子是在偷懒还是遇到了理解障碍"、"这道题的解法虽然格式不标准但思路正确", 需要的不是准确率,而是情境理解与职业判断——这正是教师区别于模型的地方。
AI 工具可以帮你做更多,但不能替你承担判断的责任。
给未来教师的提醒
模型只是从历史数据中学习了统计模式。当你在教室里使用 AI 工具——无论是自动批改、 学情预测,还是智能推题——请记住:
追问数据从哪来,是尊重学生的起点;
追问对谁不公平,是教育伦理的底线;
追问指标之外丢了什么,是你作为教师存在的意义。
模型只是从历史数据中学习了统计模式。当你在教室里使用 AI 工具——无论是自动批改、 学情预测,还是智能推题——请记住:
追问数据从哪来,是尊重学生的起点;
追问对谁不公平,是教育伦理的底线;
追问指标之外丢了什么,是你作为教师存在的意义。