给定文本上下文 $x$,LLM 计算下一个词的概率分布:
$$P(\text{下一个词} \mid \text{上下文 }x)$$
聊天机器人的完整流程:
① 将「系统提示 + 用户问题」拼接为上下文
② 从概率分布中采样一个词
③ 追加到上下文末尾
④ 重复 ②③,直到生成结束符
若每次都选最高概率的词,输出会过于单调重复。实际系统会按概率随机采样,允许低概率词偶尔入选,使生成更自然流畅。
这意味着:模型本身是确定的数学函数,但由于采样引入了随机性,同一个问题每次会得到不同的回答。
Token 是模型处理语言的最小单位,可以是一个汉字、一个英文词或词的一部分(子词)。
英文例子:education → educ + ation
中文:一般每个汉字是一个 Token
GPT 系列模型约有 100,000 种不同 Token。
每个 Token 被映射为一个高维向量,例如 GPT-3 使用 12,288 维向量。
左图展示了将高维向量降维到 2D 后的效果(PCA 降维模拟):
• 🔵 相同颜色区域 = 语义相近的词聚在一起
• 点击任意词 → 高亮显示最近邻
经典类比:国王 − 男人 + 女人 ≈ 王后
训练过程(反向传播)只能对连续数值求梯度。将离散的词语编码为连续向量,才能让梯度下降算法自动调整模型参数——这是神经网络处理语言的基础。
处理每个词时,模型会问:「我需要关注哪些其他词来理解自己的含义?」
以「花」为例:
• 在「院子里的花开了」中 → 关注「开」「院子」→ 确定为花朵
• 在「他花了很多钱」中 → 关注「钱」→ 确定为花费
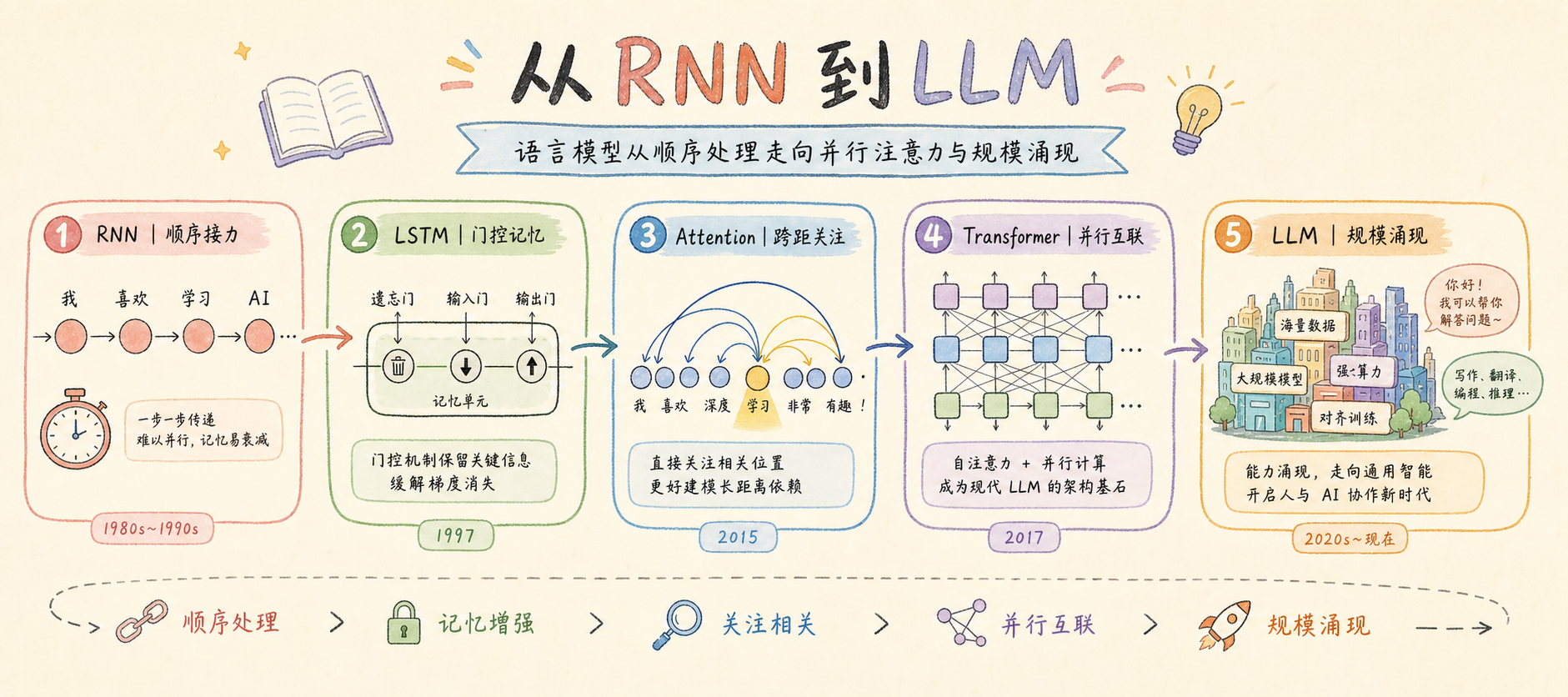
这种消歧能力是 Transformer 区别于早期 RNN 的核心优势。
RNN(2017年前):逐词处理,后面的词只能依次"接力"获取前面词的信息
Transformer(2017):所有词同时互相"交流",一次处理整个句子,可充分并行——这使 GPU 大规模训练成为可能。
实际的 Transformer 有多个注意力头(如 GPT-3 有 96 个头)并行运行。不同的头可以同时关注语法关系、语义关系、指代关系等不同维度——就像用多个视角同时理解同一句话。
训练初始时,所有参数随机设置——模型只会输出乱码。
训练过程中,每次喂入一段文字的「前 n−1 个词」,让模型预测「第 n 个词」,再用反向传播微调所有参数,使模型更倾向于输出正确答案。
对数万亿个样本重复这一过程后,模型开始能对从未见过的文本做出合理预测。
GPU(图形处理器)专为大规模并行计算设计,可同时执行数千个矩阵运算。Transformer 的注意力计算天然适合并行,使得用数万块 GPU 组成集群来训练大模型成为可能。
没有任何工程师手动设置过这 1750 亿个参数。它们完全由训练数据和反向传播算法自动决定——这也是为什么我们很难解释模型为何做出特定预测。
Reinforcement Learning from Human Feedback
= 基于人类反馈的强化学习
| R — 强化 | 对好回答给予奖励,让模型趋向更优行为 |
| L — 学习 | 通过 PPO 等算法持续调整模型参数 |
| H — 人类 | 由真实标注员提供偏好判断,而非程序规则 |
| F — 反馈 | 标注员对两条回答作出「哪个更好」的比较打分 |
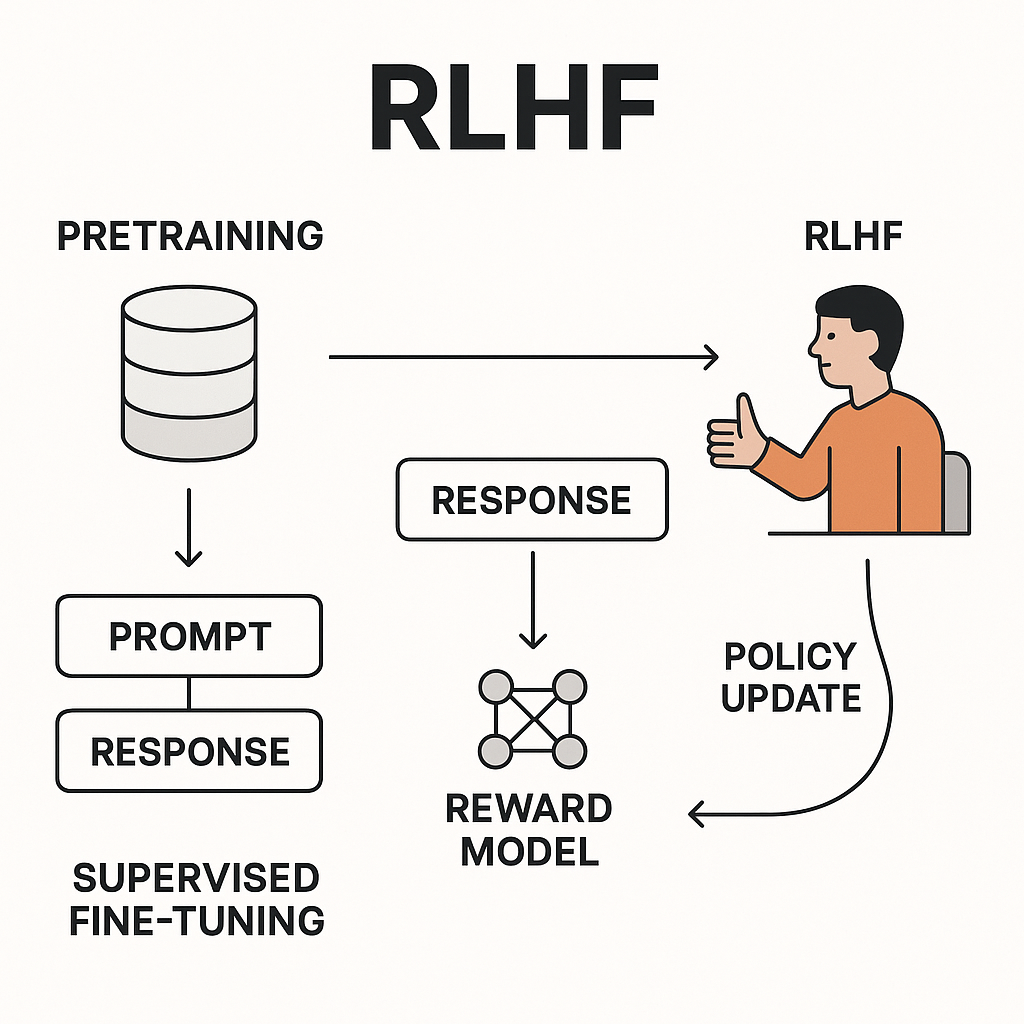
预训练(左)让模型从海量文本中学会语言规律,输出的是一个擅长续写的「文字接龙机器」; RLHF(右)让人类标注员对回答打分,训练奖励模型,再用强化学习把参数推向「人类偏好」的方向,才最终变成有用的助手。
RLHF 让模型学会产生人类喜欢的回答,但「讨人喜欢」≠「真实正确」。这可能导致模型过度自信、回避不确定性,甚至「幻觉」(生成听起来合理但错误的内容)——这是当前 AI 对齐研究的核心挑战。
模型先输出每个词的原始分数(logit),再通过带温度的 Softmax 转换为概率:
• T → 0:最高分词概率趋近 1,其他趋近 0(贪婪解码)
• T = 1:标准概率分布
• T → ∞:所有词概率趋于相等(完全随机)
T ≈ 0.3–0.7:代码生成、事实问答(高确定性)
T ≈ 0.7–1.0:对话助手、文字润色(平衡)
T ≈ 1.0–1.5:创意写作、头脑风暴(多样性)
T > 1.5:通常质量下降,较少使用
给定相同上下文,模型每次输出的 logit 完全相同。正是采样步骤中的随机性,导致了同一问题的不同回答。
-
1980s
循环神经网络 RNN
顺序逐词处理,长文本记忆衰退,无法并行,训练极慢 -
1997
LSTM(长短期记忆网络)
Hochreiter & Schmidhuber,用门控结构缓解梯度消失,但仍是顺序处理 -
2015
Attention 机制引入
Bahdanau 等人首次将注意力用于机器翻译,允许模型关注输入的不同部分 -
2017
Transformer ——《Attention Is All You Need》
Vaswani 等 8 人(Google Brain),完全抛弃 RNN,纯注意力结构,并行高效——现代 LLM 的基石 -
2018
BERT(双向 Transformer)
Google,双向上下文理解,NLP 各项基准测试大幅突破 -
2019
GPT-2(OpenAI)
15 亿参数,生成质量惊艳学界,引发"AI 写作"的广泛讨论 -
2020
GPT-3
1750 亿参数,few-shot 学习能力令研究界震惊 -
2022
ChatGPT 破圈
RLHF 对齐 + 对话界面,5 天用户破百万,大众进入"LLM 时代" -
2023+
多模型并立
GPT-4、Claude、Gemini、文心一言、通义千问、Llama…进入生态繁荣期

充分利用 GPU 长上下文
保留更多信息 可扩展
催生涌现能力
模型扩展到足够大后,会突然获得小模型完全不具备的能力(如推理、算术),这种"量变引发质变"的现象至今仍是研究热点,机制尚不完全清楚。

LLM 没有身体感知、没有因果推理、没有持续记忆。它的「理解」是一种模式匹配,而非概念建构。在课堂上,帮助学生区分这两者,是培养 AI 素养的关键。
教育评价的转向建议:从「结果正确」转向「过程可见」,从「标准答案」转向「论证与反思」,从「个人独立」转向「人机协作的批判性使用」。
教学建议:先让学生独立思考并形成判断,再用 AI 辅助验证与扩展;教会学生对 AI 输出进行事实核查与批判性评估,而不是直接接受。

最好的 AI 教育,不是教会学生怎么用 ChatGPT 完成作业,而是帮助学生理解:AI 是怎么工作的、它能做什么、它不能做什么、以及我们应该在它做不到的地方发展真正属于人类的能力。