第一步:认识数据
机器学习的一切从数据开始。这里我们用一个经典例子:根据房屋面积预测房价。
每个数据点代表一套房子——横轴是面积(平方米),纵轴是价格(万元)。
什么是数据集?
在监督学习中,每个样本有:
• 特征 (Feature) x:输入,即房屋面积
• 标签 (Label) y:输出,即房价
我们的目标:找到 x 与 y 之间的规律,使得给定面积时能预测价格。
在监督学习中,每个样本有:
• 特征 (Feature) x:输入,即房屋面积
• 标签 (Label) y:输出,即房价
我们的目标:找到 x 与 y 之间的规律,使得给定面积时能预测价格。
观察一下
面积越大,价格往往越高——它们之间存在明显的线性趋势。 我们可以用一条直线来描述这个规律,这就是线性回归的核心思想。
面积越大,价格往往越高——它们之间存在明显的线性趋势。 我们可以用一条直线来描述这个规律,这就是线性回归的核心思想。
数据预览(前 8 条)
第二步:划分数据集
训练模型前,必须将数据集划分为训练集和测试集。
点击按钮查看划分效果,理解为什么这一步不可或缺。
训练集(0个)
测试集(0个)
为什么要划分数据集?
想象你在备考:
• 训练集 = 平时做的练习题,用来学习
• 测试集 = 最终考试卷,用来检验效果
如果用考试题练习,再用同样的题考试,成绩就没有参考价值——模型也一样!
想象你在备考:
• 训练集 = 平时做的练习题,用来学习
• 测试集 = 最终考试卷,用来检验效果
如果用考试题练习,再用同样的题考试,成绩就没有参考价值——模型也一样!
过拟合 vs. 泛化能力
• 过拟合:模型在训练集上表现极好,但在测试集上表现差(死记硬背)
• 泛化:模型对从未见过的数据也能做出准确预测(举一反三)
测试集就是衡量泛化能力的工具。
• 过拟合:模型在训练集上表现极好,但在测试集上表现差(死记硬背)
• 泛化:模型对从未见过的数据也能做出准确预测(举一反三)
测试集就是衡量泛化能力的工具。
常见的划分比例
• 70% 训练 / 30% 测试(本演示)
• 80% 训练 / 20% 测试(最常用)
• 60% 训练 / 20% 验证 / 20% 测试(需要调参时)
• 70% 训练 / 30% 测试(本演示)
• 80% 训练 / 20% 测试(最常用)
• 60% 训练 / 20% 验证 / 20% 测试(需要调参时)
第三步:建立模型
线性回归的模型就是一条直线:$\hat{y} = w \cdot x + b$。
参数 $w$(斜率)和 $b$(截距)决定了直线的形状。
拖动滑块,亲手感受参数如何改变模型,以及损失函数 MSE 如何衡量好坏。
训练集
测试集
当前模型
误差线
0.00 0.00
训练集损失 MSE
—
测试集损失 MSE
—
均方误差 MSE
$\text{MSE} = \frac{1}{n}\sum_{i=1}^{n}(\hat{y}_i - y_i)^2$,即每个样本误差平方的平均值。
图中红色虚线是每个点的误差。MSE 越小,模型越好。
试试能把 MSE 调到多小?
$\text{MSE} = \frac{1}{n}\sum_{i=1}^{n}(\hat{y}_i - y_i)^2$,即每个样本误差平方的平均值。
图中红色虚线是每个点的误差。MSE 越小,模型越好。
试试能把 MSE 调到多小?
第四步:训练模型(梯度下降)
手动调参太费力了!计算机用梯度下降算法自动寻找最优参数。
点击"开始训练",观察直线如何逐步靠近数据,以及损失如何下降。
训练集
测试集
当前模型
训练集损失
0.000 0.000
训练轮次 Epoch
0
训练集损失 MSE
—
学习率 $\alpha$
$0.05$
梯度下降的直觉
想象你站在山丘上,目标是走到最低点(损失最小)。 梯度告诉你"哪个方向是下坡",每次沿下坡方向走一小步,最终抵达谷底。
学习率决定步子大小:太大会越过最低点,太小收敛很慢。
想象你站在山丘上,目标是走到最低点(损失最小)。 梯度告诉你"哪个方向是下坡",每次沿下坡方向走一小步,最终抵达谷底。
学习率决定步子大小:太大会越过最低点,太小收敛很慢。
训练速度:
自动训练随时可暂停,暂停后可单步推进,或点击「继续训练」恢复自动训练
第五步:评估模型
训练完成后,用测试集评估模型的真实性能。
测试集数据从未参与训练——它们代表模型在"现实世界"中遇到的新数据。
训练集
测试集
训练好的模型
真实规律(参考)
? ?
训练集 MSE
—
测试集 MSE
—
真实参数
$w=0.5,\ b=20$
结果分析
请先完成第四步的训练。
请先完成第四步的训练。
完整的机器学习流程
① 收集数据 → ② 划分训练/测试集 → ③ 选择模型 → ④ 训练(梯度下降) → ⑤ 测试集评估 → ⑥ 部署使用
① 收集数据 → ② 划分训练/测试集 → ③ 选择模型 → ④ 训练(梯度下降) → ⑤ 测试集评估 → ⑥ 部署使用
第六步:回归一词的由来——Galton 与师范生的统计陷阱
你知道"regression"(回归)这个词是从哪里来的吗?它最初根本不是机器学习术语,而是一位 19 世纪博物学家研究遗传时发现的统计规律。这个规律,今天仍在悄悄影响着每一间教室。
Francis Galton 与"回归"的诞生
人物
Francis Galton(1822–1911)
达尔文的表弟,英国博物学家、统计学家、地理学家、气象学家。一生横跨多个领域,被誉为"统计学的奠基人之一"。他发明了相关系数、标准差等概念,奠定了现代统计学基础。
达尔文的表弟,英国博物学家、统计学家、地理学家、气象学家。一生横跨多个领域,被誉为"统计学的奠基人之一"。他发明了相关系数、标准差等概念,奠定了现代统计学基础。
1877
豌豆种子实验
Galton 让朋友们种植不同大小的豌豆,发现父代豆粒特别大或特别小时,子代豆粒往往比父代更"接近平均"。这是"回归到均值"的最早文字记录。
Galton 让朋友们种植不同大小的豌豆,发现父代豆粒特别大或特别小时,子代豆粒往往比父代更"接近平均"。这是"回归到均值"的最早文字记录。
1885
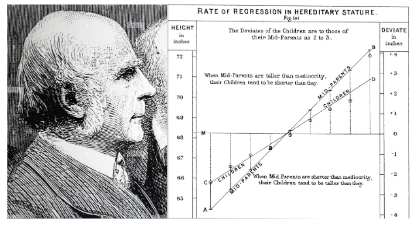
父母与孩子的身高研究
Galton 收集了 928 对父母与成年子女的身高数据,发现:非常高的父母,孩子往往比父母矮一些;非常矮的父母,孩子往往比父母高一些——极端值会向群体均值"回退"。
Galton 收集了 928 对父母与成年子女的身高数据,发现:非常高的父母,孩子往往比父母矮一些;非常矮的父母,孩子往往比父母高一些——极端值会向群体均值"回退"。
1886
Galton 发表论文 Regression towards mediocrity in hereditary stature,正式命名这一现象为 "regression"(回归)。
这就是今天"线性回归""逻辑回归"中"回归"二字的真正起源。
这就是今天"线性回归""逻辑回归"中"回归"二字的真正起源。
历史的复杂性
Galton 同时也是"优生学"(eugenics)一词的提出者,并将其与回归研究结合,后世因此引发了严重的伦理争议。这提醒我们:同一位科学家的工作,可以同时包含伟大的发现与危险的偏见。科学本身是工具,如何使用取决于人的价值观。
Galton 同时也是"优生学"(eugenics)一词的提出者,并将其与回归研究结合,后世因此引发了严重的伦理争议。这提醒我们:同一位科学家的工作,可以同时包含伟大的发现与危险的偏见。科学本身是工具,如何使用取决于人的价值观。
📊
陷阱一:回归到均值
最常被误读的统计现象
第一次考试:小明 30 分,小红 95 分
第二次考试:小明 55 分(+25),小红 80 分(-15)
结论是"严厉批评小明有效,表扬小红反而退步"?
未必。 两次成绩的变化很可能只是随机波动向均值回归,与你的干预无关。
教师若把回归现象当成教学效果,会形成错误的"惩罚有效、奖励无效"幻觉。
第二次考试:小明 55 分(+25),小红 80 分(-15)
结论是"严厉批评小明有效,表扬小红反而退步"?
未必。 两次成绩的变化很可能只是随机波动向均值回归,与你的干预无关。
教师若把回归现象当成教学效果,会形成错误的"惩罚有效、奖励无效"幻觉。
🔄
陷阱二:辛普森悖论
分组看与合并看,结论相反
A 班平均分 70(基础好);B 班平均分 65(基础弱)。
合并后全年级平均分 66——B 班人数多,把整体拉低了。
如果只看合并数据,会误以为 A 班教学没带来优势。
教育数据必须注意分组结构,否则结论可能完全反转。
合并后全年级平均分 66——B 班人数多,把整体拉低了。
如果只看合并数据,会误以为 A 班教学没带来优势。
教育数据必须注意分组结构,否则结论可能完全反转。
⚠️
陷阱三:相关 ≠ 因果
线性回归只描述关联
小学生的身高与词汇量高度正相关(r ≈ 0.9)。
但"长高"并不会让孩子词汇变多——背后的真实原因是年龄增长(潜在变量)。
线性回归可以告诉你两个变量之间"有多强的线性关联",但不能告诉你谁导致了谁。
但"长高"并不会让孩子词汇变多——背后的真实原因是年龄增长(潜在变量)。
线性回归可以告诉你两个变量之间"有多强的线性关联",但不能告诉你谁导致了谁。
给未来教师的提醒
模型只会描述数据中的模式,不会替你判断因果。当你在教室里用数据做决策——无论是排座位、分层教学还是评估教学效果——都要记住:相关性是起点,不是终点。
模型只会描述数据中的模式,不会替你判断因果。当你在教室里用数据做决策——无论是排座位、分层教学还是评估教学效果——都要记住:相关性是起点,不是终点。
第七步:大道至简——从 Galton 到 GPT 的线性力量
从一条拟合身高数据的直线,到今天能写文章、做翻译、写代码的大语言模型——它们之间的距离,比你想象的近得多。核心思想两百年来从未改变:加权求和,再加非线性。
两百年的线性传承
1805
Legendre 最小二乘法
法国数学家 Legendre 提出"最小化残差平方和"来拟合观测数据,用于天文轨道计算。这是线性回归的数学基础。
法国数学家 Legendre 提出"最小化残差平方和"来拟合观测数据,用于天文轨道计算。这是线性回归的数学基础。
1809
Gauss 定位谷神星
高斯用最小二乘法从少量观测数据中预测谷神星的轨道,成功定位——这是"用数据拟合模型来预测"的历史性案例。
高斯用最小二乘法从少量观测数据中预测谷神星的轨道,成功定位——这是"用数据拟合模型来预测"的历史性案例。
1885
Galton 赋予统计意义
将最小二乘从天文学带入生物学与社会科学,催生了现代统计学(相关、回归、方差分析)。
将最小二乘从天文学带入生物学与社会科学,催生了现代统计学(相关、回归、方差分析)。
20世纪
经济学与社会科学的支柱
线性回归成为计量经济学、心理测量、医学临床研究的标准工具,支撑了无数政策决策。
线性回归成为计量经济学、心理测量、医学临床研究的标准工具,支撑了无数政策决策。
1957
感知机:加权求和 + 阈值
Rosenblatt 的感知机本质上就是一个线性分类器——加权求和后过一个阶跃函数。神经网络的故事从这里出发。
Rosenblatt 的感知机本质上就是一个线性分类器——加权求和后过一个阶跃函数。神经网络的故事从这里出发。
2017
Transformer:注意力即加权求和
论文 "Attention Is All You Need" 提出的注意力机制,核心计算仍是:对所有词向量做加权平均。只是权重本身是动态学习出来的。
论文 "Attention Is All You Need" 提出的注意力机制,核心计算仍是:对所有词向量做加权平均。只是权重本身是动态学习出来的。
2022
ChatGPT 引爆全球
数千亿参数,本质上仍是大量线性变换(矩阵乘法)+ 非线性激活函数(如 GELU)的层叠。只是规模大到令人难以想象。
数千亿参数,本质上仍是大量线性变换(矩阵乘法)+ 非线性激活函数(如 GELU)的层叠。只是规模大到令人难以想象。
同一个核心,不同的语境
线性回归
$$\hat{y} = w \cdot x + b$$
单层神经元(神经网络页学过)
$$y = \sigma\!\left(\sum_i w_i x_i + b\right)$$
Transformer 注意力(简化)
$$\operatorname{Attn}(Q,K,V) = \operatorname{softmax}\!\left(\frac{QK^\top}{\sqrt{d}}\right)V$$
三个公式,一个本质:对输入做加权求和,再过一个非线性函数。区别只是权重的数量从 2 个变成了数千亿个。
核心洞察:复杂源于简单的层叠
ChatGPT 的神秘感,来自参数量和训练数据的规模,而不是某个全新的数学原理。你今天拖动的那根滑块、调整的那个斜率,正是所有大模型最基本的计算单元。
ChatGPT 的神秘感,来自参数量和训练数据的规模,而不是某个全新的数学原理。你今天拖动的那根滑块、调整的那个斜率,正是所有大模型最基本的计算单元。
给未来教师的话
当学生问你"ChatGPT 有没有意识?",你可以告诉他们:
"它的每一步计算,都和我们课上调过的滑块一样朴素。神奇之处在于规模与数据,而不是神秘。"
去神秘化,是 AI 素养教育最重要的第一步。
"它的每一步计算,都和我们课上调过的滑块一样朴素。神奇之处在于规模与数据,而不是神秘。"
去神秘化,是 AI 素养教育最重要的第一步。