第一步:激活函数——给神经网络加入非线性
在前面的神经网络案例中,我们假设神经元只做线性计算(加权求和)。
但纯线性网络的表达能力非常有限——无论叠多少层,最终都等价于一个线性函数。
激活函数的作用就是在加权求和之后加入非线性变换,让网络能够学习更复杂的规律。
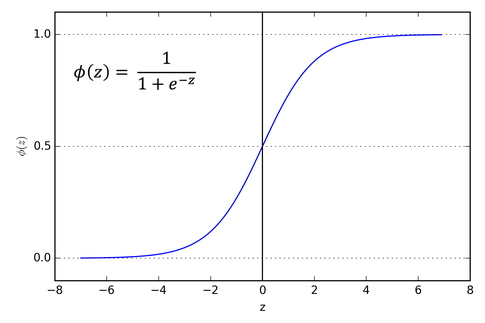
Sigmoid 函数 $\sigma(z)$
线性函数 $y = z$(对比)
为什么需要非线性?
假设没有激活函数,两层网络:$y = \textcolor{orange}{w_2}(\textcolor{blue}{w_1}x + \textcolor{blue}{b_1}) + \textcolor{orange}{b_2} = (\textcolor{orange}{w_2}\textcolor{blue}{w_1})x + (\textcolor{orange}{w_2}\textcolor{blue}{b_1} + \textcolor{orange}{b_2})$
蓝色 = 第一层参数($w_1, b_1$) · 橙色 = 第二层参数($w_2, b_2$)
化简后仍是一个线性函数!无论叠多少层,都无法表达 XOR 等非线性关系。 激活函数让网络能够逼近任意复杂的函数。
假设没有激活函数,两层网络:$y = \textcolor{orange}{w_2}(\textcolor{blue}{w_1}x + \textcolor{blue}{b_1}) + \textcolor{orange}{b_2} = (\textcolor{orange}{w_2}\textcolor{blue}{w_1})x + (\textcolor{orange}{w_2}\textcolor{blue}{b_1} + \textcolor{orange}{b_2})$
蓝色 = 第一层参数($w_1, b_1$) · 橙色 = 第二层参数($w_2, b_2$)
化简后仍是一个线性函数!无论叠多少层,都无法表达 XOR 等非线性关系。 激活函数让网络能够逼近任意复杂的函数。
Sigmoid 函数
$$\sigma(z) = \frac{1}{1 + e^{-z}}$$
神经元的完整计算过程
Step 1(线性加权):$z = w_1x_1 + w_2x_2 + \cdots + b$
Step 2(非线性激活):$a = \sigma(z)$
Sigmoid 的特点
• 输出范围始终在 $(0, 1)$ 之间,适合表示概率
• 当 $z \to +\infty$ 时,$\sigma(z) \to 1$;当 $z \to -\infty$ 时,$\sigma(z) \to 0$
• $z = 0$ 时,$\sigma(0) = 0.5$
在反向传播中,我们还需要知道 $\sigma$ 的导数:$\sigma'(z) = \sigma(z)(1 - \sigma(z))$
• 输出范围始终在 $(0, 1)$ 之间,适合表示概率
• 当 $z \to +\infty$ 时,$\sigma(z) \to 1$;当 $z \to -\infty$ 时,$\sigma(z) \to 0$
• $z = 0$ 时,$\sigma(0) = 0.5$
在反向传播中,我们还需要知道 $\sigma$ 的导数:$\sigma'(z) = \sigma(z)(1 - \sigma(z))$
为什么用 Sigmoid 做激活函数?
Sigmoid 并非来自物理或生物现象,而是由比利时数学家 Pierre Verhulst(1838–1847)为建模人口增长而人工构造的 Logistic 函数。它被神经网络选作激活函数有三个原因:
● 导数形式极其简洁:$\sigma'(z) = \sigma(z)(1 - \sigma(z))$,只需知道 $\sigma(z)$ 的值就能算出导数。在反向传播中每层都要计算梯度,这个性质让计算量大幅降低。
● 输出范围 $(0,1)$:天然适合表示概率,用于二分类问题时输出层可以直接解释为"属于正类的概率"。
● 光滑可微:处处可导,适合基于梯度的优化方法。
它的主要局限是两端饱和(梯度接近 0),深层网络中容易导致梯度消失,因此后来的深度网络多用 ReLU 替代隐藏层的激活函数。
Sigmoid 并非来自物理或生物现象,而是由比利时数学家 Pierre Verhulst(1838–1847)为建模人口增长而人工构造的 Logistic 函数。它被神经网络选作激活函数有三个原因:
● 导数形式极其简洁:$\sigma'(z) = \sigma(z)(1 - \sigma(z))$,只需知道 $\sigma(z)$ 的值就能算出导数。在反向传播中每层都要计算梯度,这个性质让计算量大幅降低。
● 输出范围 $(0,1)$:天然适合表示概率,用于二分类问题时输出层可以直接解释为"属于正类的概率"。
● 光滑可微:处处可导,适合基于梯度的优化方法。
它的主要局限是两端饱和(梯度接近 0),深层网络中容易导致梯度消失,因此后来的深度网络多用 ReLU 替代隐藏层的激活函数。
第二步:问题引入——训练神经网络需要什么?
我们已经知道神经网络如何通过前向传播产生输出。但输出的结果往往有误差,
需要不断调整权重来让预测越来越准。问题在于:网络中有那么多权重,
怎么知道每个权重该调多少?这就是反向传播要解决的问题。
输入层
隐藏层
输出层
权重
调整权重与偏置
拖动滑块(−2.00 ~ +2.00),算式与损失实时更新
输入层 → 隐藏层
$w(x_1, h_1)$
0.40
$w(x_1, h_2)$
0.20
$w(x_2, h_1)$
0.10
$w(x_2, h_2)$
0.60
$b(h_1)$
0.10
$b(h_2)$
0.20
隐藏层 → 输出层
$w(h_1, y)$
0.50
$w(h_2, y)$
-0.30
$b(y)$
0.10
前向传播结果
误差(损失)
核心问题
你是否注意到:改变权重会影响损失的大小?
反向传播算法正是计算出每个权重应该朝哪个方向调、调多少,让损失下降最快——而不是盲目地逐一尝试。
你是否注意到:改变权重会影响损失的大小?
反向传播算法正是计算出每个权重应该朝哪个方向调、调多少,让损失下降最快——而不是盲目地逐一尝试。
第三步:链式法则的直觉——误差如何分配?
反向传播从输出层出发,沿计算路径逐步推导每个参数(权重和偏置)的梯度,再用梯度更新参数。
图中 红色连线 表示正梯度(需减小权重),
蓝色连线 表示负梯度(需增大权重);
节点下方同时显示偏置值(紫色)和偏置梯度(彩色)。
输入层
隐藏层
输出层
正梯度(权重需减小)
负梯度(权重需增大)
核心思路
损失 $L$ 是网络中所有参数(权重 $\mathbf{W}$、偏置 $\mathbf{b}$)的函数,可写成复合函数:
损失 $L$ 是网络中所有参数(权重 $\mathbf{W}$、偏置 $\mathbf{b}$)的函数,可写成复合函数:
$$L(\mathbf{W}, \mathbf{b}) = L\bigl(\sigma(\mathbf{z}(\mathbf{W}, \mathbf{b})),\; y_{\text{true}}\bigr)$$
要求某个参数的偏导数,只需沿着"损失 → 输出 → ... → 该参数"的路径,用链式法则把每一步的导数相乘。
输出层的计算
先看输出层是怎么从前面的结果算出来的(先写抽象函数,再写具体表达式):
$$z_o = f_z(h, w_o, b_o) = w_{o,1}h_1 + w_{o,2}h_2 + b_o$$
$$y = f_y(z_o) = \sigma(z_o)$$
$$L = f_L(y) = \frac{1}{2}(y - y_{\text{true}})^2$$
$z_o$ 是加权求和,$y = \sigma(z_o)$ 是经过激活后的预测值,$L$ 是损失。箭头方向:$w_{o,1} \to z_o \to y \to L$。
求输出层权重 $w_{o,1}$ 的梯度
从损失 $L$ 到权重 $w_{o,1}$ 的计算路径:
$$L \;\longrightarrow\; y \;\longrightarrow\; z_o \;\longrightarrow\; w_{o,1}$$
根据链式法则,把每一步的导数相乘。注意 $\sigma'(z_o) = \sigma(z_o)(1-\sigma(z_o)) = y(1-y)$:
$$\frac{\partial L}{\partial w_{o,1}} = \underbrace{\frac{\partial L}{\partial y}}_{y-y_{\text{true}}} \cdot \underbrace{\frac{\partial y}{\partial z_o}}_{y(1-y)} \cdot \underbrace{\frac{\partial z_o}{\partial w_{o,1}}}_{h_1}$$
代入后:$\displaystyle \frac{\partial L}{\partial w_{o,1}} = (y - y_{\text{true}}) \cdot y(1-y) \cdot h_1$
求隐藏层权重 $w_{x_1,h_1}$ 的梯度
隐藏层的计算(同样先抽象后具体):
$$z_{h1} = f_z(x, w_h, b_h) = w_{x_1,h_1}x_1 + w_{x_2,h_1}x_2 + b_{h1}$$
$$h_1 = f_h(z_{h1}) = \sigma(z_{h1})$$
从损失到该权重的路径更长,同样把每一步的导数相乘:
$$L \;\longrightarrow\; y \;\longrightarrow\; z_o \;\longrightarrow\; h_1 \;\longrightarrow\; z_{h1} \;\longrightarrow\; w_{x_1,h_1}$$
$$\frac{\partial L}{\partial w_{x_1,h_1}} = \underbrace{\frac{\partial L}{\partial y}}_{y-y_{\text{true}}} \cdot \underbrace{\frac{\partial y}{\partial z_o}}_{y(1-y)} \cdot \underbrace{\frac{\partial z_o}{\partial h_1}}_{w_{o,1}} \cdot \underbrace{\frac{\partial h_1}{\partial z_{h1}}}_{h_1(1-h_1)} \cdot \underbrace{\frac{\partial z_{h1}}{\partial w_{x_1,h_1}}}_{x_1}$$
梯度 = 路径上每一步局部导数的乘积。正负号自然由各项的符号共同决定。
前向传播 vs. 反向传播
• 前向传播:数据从左→右,加权求和 → 激活,得到预测值
• 反向传播:从损失出发从右→左,每一步求局部导数,相乘得到梯度
下一步将代入具体数值,逐步算出每个权重的梯度。
• 前向传播:数据从左→右,加权求和 → 激活,得到预测值
• 反向传播:从损失出发从右→左,每一步求局部导数,相乘得到梯度
下一步将代入具体数值,逐步算出每个权重的梯度。
第四步:每个权重的"责任"——梯度计算
知道了误差信号如何分配,现在我们来计算梯度——也就是每个权重对总损失的影响程度。
梯度告诉我们要把权重往哪个方向调、调多少。点击下方按钮,查看不同层级权重的梯度计算过程。
输入层
隐藏层
输出层
正梯度(权重需减小)
负梯度(权重需增大)
输出层梯度计算
先求损失对预测值的偏导:
\frac{\partial L}{\partial y} = y - y_{\text{true}}激活函数导数:
\sigma'(z_o) = y(1-y)链式法则,输出层权重梯度:
$$\frac{\partial L}{\partial w_{o,j}} = \underbrace{(y - y_{\text{true}})}_{\frac{\partial L}{\partial y}} \cdot \underbrace{y(1-y)}_{\sigma'(z_o)} \cdot \underbrace{h_j}_{\frac{\partial z_o}{\partial w_{o,j}}}$$
偏置的系数恒为 1,所以偏置梯度 = $(y - y_{\text{true}}) \cdot y(1-y)$
梯度的正负号含义
• 正梯度:增大权重会让损失变大 → 应该减小权重
• 负梯度:增大权重会让损失变小 → 应该增大权重
这就是为什么更新公式是:$w_{\text{new}} = w_{\text{old}} - \eta \times \frac{\partial L}{\partial w}$
• 正梯度:增大权重会让损失变大 → 应该减小权重
• 负梯度:增大权重会让损失变小 → 应该增大权重
这就是为什么更新公式是:$w_{\text{new}} = w_{\text{old}} - \eta \times \frac{\partial L}{\partial w}$
第五步:一次完整的训练迭代
现在我们把所有步骤串联起来:前向传播 → 计算损失 → 反向传播 → 更新权重。
点击"执行一步",观察网络参数如何变化,损失如何下降。
输入层
隐藏层
输出层
正梯度(权重需减小)
负梯度(权重需增大)
迭代次数
0
当前损失 MSE
—
学习率
0.1
权重更新公式
$$w_{\text{新}} = w_{\text{旧}} - \textcolor{#d97706}{\alpha} \times \frac{\partial L}{\partial w}$$
$\alpha$ = 0.1(学习率) — 控制每次更新的步长大小
超参数(Hyperparameter)是指在训练开始前由人工设定、而非由模型自己学习得到的参数。学习率 $\alpha$ 就是一个典型的超参数——它不会在反向传播过程中被更新,需要我们根据经验或实验来选取合适的值。
观察要点
每次迭代包含 4 个步骤:① 前向传播计算输出 → ② 计算损失 → ③ 反向传播求梯度 → ④ 更新权重。
注意观察:损失曲线应该整体呈下降趋势,说明网络正在"学习"。
每次迭代包含 4 个步骤:① 前向传播计算输出 → ② 计算损失 → ③ 反向传播求梯度 → ④ 更新权重。
注意观察:损失曲线应该整体呈下降趋势,说明网络正在"学习"。
第六步:反向传播背后的人——Geoffrey Hinton
反向传播算法从提出到改变世界,历经数十年坎坷。这一算法背后,有一位"深度学习之父"用半生的坚守,将它从学术冷门变成了 AI 革命的基石。
反向传播简史
1969
AI 寒冬降临
Minsky & Papert 出版《感知机》,证明单层神经网络无法解决 XOR 问题,神经网络研究陷入低谷。
Minsky & Papert 出版《感知机》,证明单层神经网络无法解决 XOR 问题,神经网络研究陷入低谷。
1974
初次提出
Paul Werbos 在博士论文中首次推导出反向传播的数学形式,但几乎无人关注。
Paul Werbos 在博士论文中首次推导出反向传播的数学形式,但几乎无人关注。
1986
划时代论文
Rumelhart、Hinton、Williams 在 Nature 发表
"Learning representations by back-propagating errors",反向传播正式成为训练多层神经网络的核心方法。
Rumelhart、Hinton、Williams 在 Nature 发表
"Learning representations by back-propagating errors",反向传播正式成为训练多层神经网络的核心方法。
2006
深度学习复兴
Hinton 提出深度置信网络(Deep Belief Networks),开启深度学习新纪元。
Hinton 提出深度置信网络(Deep Belief Networks),开启深度学习新纪元。
2012
ImageNet 震撼
Hinton 团队的 AlexNet 以大幅优势夺冠图像识别竞赛,深度学习走入工业界视野。
Hinton 团队的 AlexNet 以大幅优势夺冠图像识别竞赛,深度学习走入工业界视野。
2018
图灵奖
与 Yoshua Bengio、Yann LeCun 共同获得计算机科学最高荣誉——ACM 图灵奖,三人并称"深度学习三巨头"。
与 Yoshua Bengio、Yann LeCun 共同获得计算机科学最高荣誉——ACM 图灵奖,三人并称"深度学习三巨头"。
2023
离开 Google
Hinton 从谷歌辞职,坦言希望能自由讨论 AI 的潜在风险,呼吁各界重视 AI 安全。
Hinton 从谷歌辞职,坦言希望能自由讨论 AI 的潜在风险,呼吁各界重视 AI 安全。
2024
诺贝尔物理学奖
与 John Hopfield 共同获奖,表彰其"用人工神经网络实现机器学习的基础性发现与发明"。
与 John Hopfield 共同获奖,表彰其"用人工神经网络实现机器学习的基础性发现与发明"。

🏆
2018 ACM 图灵奖
计算机科学领域的"诺贝尔奖"
授予 Hinton、Bengio、LeCun 三人,表彰他们在深度神经网络领域的概念与工程突破,使深度学习成为现代计算技术的重要组成部分。
🎖️
2024 诺贝尔物理学奖
与 John Hopfield 共同获奖
诺贝尔委员会指出,他们的工作"利用物理学工具,构建了能够学习的神经网络方法"。这是 AI 领域首次获得诺贝尔奖,标志着机器学习对科学的根本性影响得到最高认可。
给同学们的启示
Hinton 在神经网络被主流学界否定的数十年间,坚持认为这条路是对的。反向传播算法你已经学完了——它不只是一串数学公式,更是一代研究者对"机器能否学习"这一问题的执着回答。
Hinton 在神经网络被主流学界否定的数十年间,坚持认为这条路是对的。反向传播算法你已经学完了——它不只是一串数学公式,更是一代研究者对"机器能否学习"这一问题的执着回答。